Comment a été ce contenu ?
ApprendreVoir c’est comprendre : Twelve Labs est le pionnier de l’intelligence vidéo basée sur l’IA sur AWS
Voir c’est comprendre : Twelve Labs est le pionnier de l’intelligence vidéo basée sur l’IA sur AWS
La vue est le sens dominant chez la plupart des humains et elle a un impact important sur la façon dont nous interprétons le monde qui nous entoure. Ce que nous percevons, la façon dont nous apprenons, pensons et évoluons dans notre environnement sont tous fortement influencés par la vision. Cependant, même les personnes dotées d’une vue parfaite sont limitées par la quantité d’informations que le cortex visuel peut traiter à un moment donné. Heureusement, la technologie peut aller au-delà de ce que propose la biologie.
Twelve Labs est une start-up en pleine croissance qui s’appuie sur l’IA générative pour traiter de grandes quantités de données vidéo, et ainsi offrir à ses clients une intelligence vidéo de nouvelle génération. L’entreprise entraîne et met à l’échelle des modèles d’IA multimodaux sur AWS, capables d’interpréter les données visuelles comme nous le faisons, à une échelle rendue possible par une technologie innovante et une expertise éprouvée.
Donner vie à une idée novatrice
Twelve Labs est une start-up sud-coréenne spécialisée dans l’intelligence vidéo optimisée par l’IA. La société a été cofondée par Jae Lee en 2020 et possède des bureaux à Séoul et à San Francisco. « Twelve Labs est une société de recherche et de produits en intelligence artificielle qui crée des modèles de fondation vidéo pour les entreprises et les développeurs », explique M. Lee. « Avant même d’apprendre à parler ou à écrire, nous collectons de nombreux aspects différents du monde grâce aux données d’entrée sensorielles en interagissant avec celles-ci, et nous pensons que c’est la meilleure façon de créer des modèles. »
Twelve Labs a été fondée à une époque où le marché naissant de l’IA se concentrait principalement sur le texte ou les images. « Lorsque nous avons créé l’entreprise, on ne parlait pas vraiment de multimodal et on n’utilisait même pas le terme « modèle de fondation ». Nous observions cette tendance des laboratoires et des entreprises qui tentaient d’aborder l’intelligence par la compréhension du langage. Mais nous avons alors vu une opportunité, et aussi, pour être honnête, un défi très difficile à relever, dans le domaine de la vidéo. C’est à ce moment-là que nous avons commencé à travailler sur le raisonnement perceptuel. »
« Nous nous concentrons sur les problèmes traditionnels de compréhension des vidéos, tels que la recherche sémantique dans de grandes archives, la classification, le chat vidéo, voire les agents vidéo et la génération augmentée de récupération (RAG) », explique M. Lee. « Si vous disposez de beaucoup de données vidéo et que vous devez pouvoir effectuer des recherches très rapidement, l’API de Twelve Labs vous permet de le faire en quelques minutes. » Aujourd’hui, plus de 30 000 développeurs et entreprises utilisent les modèles de Twelve Labs, y compris des marques influentes comme la NFL.
Génération d’informations image par image
Twelve Labs propose deux modèles, Marengo et Pegasus. « Marengo est dédié à la génération de riches vectorisations vidéo multimodales qui vous permettent d’effectuer n’importe quelle extraction, c’est-à-dire des images, du son, des vidéos et du texte », explique M. Lee. « Pegasus est notre modèle de langage vidéo, capable de combiner les invites des utilisateurs et les intégrations générées par Marengo pour répondre aux questions des utilisateurs, générer des rapports, etc. »
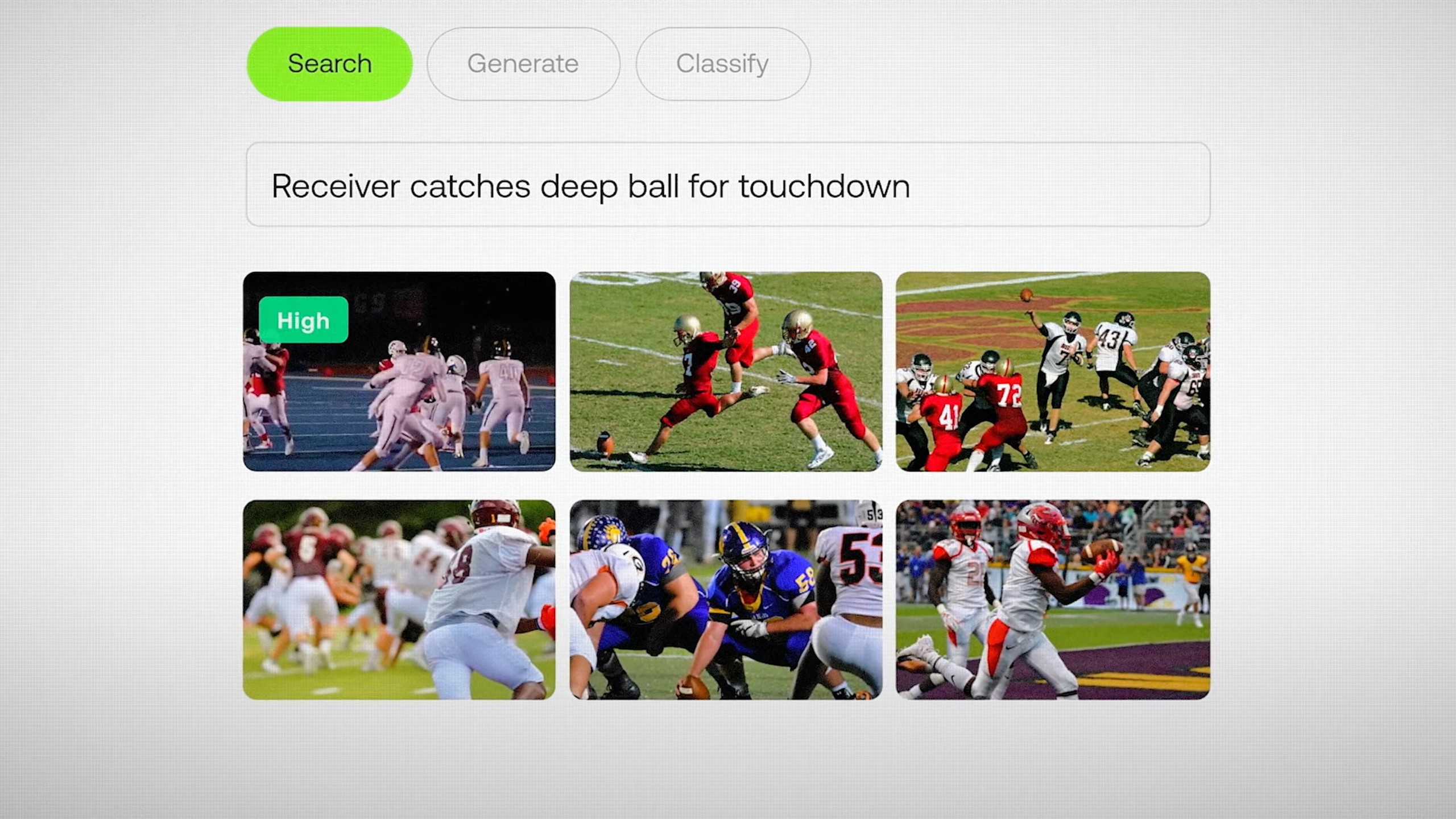
« Nous menons de nombreuses recherches innovantes sur des modèles d’architecture plus adaptés à la vidéo. Il existe une large variété de modèles de vectorisation de texte et d’images, mais la vidéo est une tout autre chose. C’est le côté recherche, mais le gros du travail d’ingénierie reste encore à faire », déclare M. Lee.
Heureusement, les start-ups spécialisées dans l’IA ont l’habitude de relever des défis techniques importants et Twelve Labs ne fait pas exception à la règle. « En fait, 80 % des données mondiales sont des vidéos, ce qui représente plus de 100 zettaoctets de contenu vidéo que nous utilisons d’abord pour entraîner, indexer et comprendre », explique M. Lee. « Le défi, c’est l’ampleur du problème. » Twelve Labs collabore avec AWS pour surmonter ce défi en accédant à la technologie et à l’expertise nécessaires en vue d’atteindre ses objectifs.
Stimuler le raisonnement perceptuel grâce à une technologie innovante
Twelve Labs utilise Amazon SageMaker HyperPod pour entraîner et mettre à l’échelle ses modèles plus efficacement. Les entreprises utilisent SageMaker HyperPod pour entraîner des modèles de fondation pendant des semaines, voire des mois, tout en surveillant activement l’état de santé du cluster et en tirant parti de la résilience automatisée des nœuds et des tâches. Si un nœud défaillant est détecté, il est automatiquement remplacé et l’entraînement des modèles reprend, ce qui permet d’économiser jusqu’à 40 % du temps d’entraînement.
« L’un des aspects les plus difficiles de la création de ces modèles est que nous travaillons avec des machines vraiment puissantes à une échelle incroyable, allant de centaines de GPU à des dizaines de milliers de processeurs », explique M. Lee. « Même si ces machines sont vraiment bien construites et robustes, il y a de nombreuses pannes matérielles et de nœuds. »
« Nous travaillons en étroite collaboration avec l’équipe SageMaker HyperPod. Nous tirons parti de la résilience et de l’infrastructure d’entraînement distribué développée par AWS, ce qui nous permet de faire tourner des GPU, d’entraîner nos modèles le plus rapidement possible et de les expédier », explique M. Lee. « La résilience de SageMaker HyperPod, sa capacité à réparer les nœuds morts et, en fait, à externaliser le calcul à haute performance nous ont vraiment séduits. »
L’équipe de Twelve Labs utilise également AWS Elemental MediaConvert pour le transcodage vidéo basé sur le cloud, ce qui évite de devoir gérer l’infrastructure de traitement vidéo. « L’infrastructure de streaming AWS Elemental MediaConvert nous permet de nous concentrer sur les domaines dans lesquels nous excellons réellement », explique M. Lee.
Twelve Labs assure également une intégration approfondie avec Amazon Simple Storage Service (Amazon S3), un service de stockage d’objets offrant une capacité de mise à l’échelle, une disponibilité des données, une sécurité et des performances de pointe. « Nos clients apprécient vraiment l’intégration harmonieuse des flux de travail Twelve Labs et S3 », déclare M. Lee. « Si vous stockez la grande majorité de vos données sur S3, nous pouvons extraire vos données vidéo de manière fluide, les indexer, les intégrer et permettre une recherche sans souci. »
Mettre l’accent sur la croissance
AWS a également aidé Twelve Labs à accélérer sa croissance grâce à AWS Activate, un programme phare qui fournit des crédits cloud, une assistance technique et un mentorat commercial aux start-ups. L’équipe AWS Startups est composée de fondateurs, de créateurs et de visionnaires qui comprennent non seulement les défis liés à la gestion de start-ups, mais qui les ont également vécus et disposent de l’expérience nécessaire pour aider les autres tout au long de leur parcours. Cela inclut la recherche des services AWS adaptés à leur cas d’utilisation, le financement d’une démonstration de faisabilité initiale, etc.
Un élément clé d’AWS Activate consiste à aider les start-ups à développer des stratégies de commercialisation et à accroître leur visibilité auprès de nouveaux clients. Dans le cadre de ce processus, Twelve Labs a rejoint AWS Marketplace, une vitrine numérique organisée qui permet à l’entreprise de proposer harmonieusement ses services d’intelligence vidéo à une clientèle mondiale. Les entreprises de toutes tailles peuvent désormais utiliser AWS Marketplace pour rechercher, essayer, acheter, déployer et gérer rapidement les produits Twelve Labs.
Une IA qui voit le monde comme nous
À l’avenir, Twelve Labs poursuivra sa collaboration avec AWS et son innovation dans le domaine de l’intelligence vidéo optimisée par l’IA. « La principale raison d’être enthousiaste à l’idée de travailler avec AWS est l’empathie partagée pour nos clients qui traitent des pétaoctets, voire des exaoctets, de données vidéo », déclare M. Lee.
« AWS nous a fourni la puissance de calcul et l’assistance nécessaires pour relever les défis de l’IA multimodale et rendre la vidéo plus accessible, et nous attendons avec impatience une collaboration fructueuse au cours des prochaines années, tandis que nous poursuivons notre innovation et que nous nous développons à l’échelle mondiale », déclare M. Lee. « Nous pouvons accélérer l’entraînement de nos modèles, proposer notre solution en toute sécurité à des milliers de développeurs dans le monde entier et contrôler les coûts de calcul, tout en repoussant les limites de la compréhension et de la création de vidéos grâce à l’IA générative. »
Dans le cadre d’un contrat de collaboration stratégique (SCA) de trois ans, la société travaille désormais avec AWS pour améliorer encore ses capacités d’entraînement des modèles et déployer ses modèles dans de nouveaux secteurs tels que la santé et l’industrie manufacturière. « Nous souhaitons être le cortex visuel de tous les futurs agents d’IA, des agents qui ont besoin de voir le monde comme nous le faisons », explique M. Lee.
Comment a été ce contenu ?