¿Qué le pareció este contenido?
Ver para comprender: Twelve Labs lidera la inteligencia de video con IA en AWS
La vista es el sentido dominante en la mayoría de los seres humanos y tiene un profundo impacto en la forma en que interpretamos el mundo que nos rodea. La visión interviene en gran medida en lo que percibimos y la forma en que aprendemos, pensamos y nos movemos por nuestro entorno. Sin embargo, incluso las personas bendecidas con una vista perfecta se ven limitadas por la cantidad de información que la corteza visual puede procesar en un momento dado. Afortunadamente, la tecnología puede ir más allá de lo que proporciona la biología.
Twelve Labs es una startup de rápido crecimiento que utiliza IA generativa para procesar grandes cantidades de datos de video, lo que permite a sus clientes disponer de inteligencia de video de próxima generación. La empresa entrena y escala modelos de IA multimodales en AWS que son capaces de interpretar los datos visuales de la misma manera que nosotros, a una escala que es posible gracias a una tecnología innovadora y a una experiencia comprobada.
Puesta en marcha de una idea general
Twelve Labs es una startup surcoreana que se centra en la inteligencia de video con tecnología de IA. La empresa fue cofundada por Jae Lee en 2020 y tiene oficinas en Seúl y San Francisco. “Twelve Labs es una empresa de investigación y productos de IA que crea modelos fundacionales de video para empresas y desarrolladores”, afirma Lee. “Incluso antes de aprender a hablar o escribir, interactuamos con los datos de entrada sensoriales para recopilar muchos aspectos diferentes del mundo y creemos que esa es la mejor manera de crear modelos”.
Twelve Labs se fundó en un momento en que el emergente mercado de la IA se centraba principalmente en texto o imágenes. “Cuando fundamos la empresa, la gente realmente no hablaba de la multimodalidad ni siquiera utilizaba el término 'modelo fundacional'. Estábamos viendo esta tendencia de laboratorios y empresas que intentaban abordar la inteligencia mediante la comprensión del lenguaje. Pero luego vimos una oportunidad (también, honestamente, un desafío muy difícil) de abordar el video. Fue entonces cuando empezamos a trabajar en el razonamiento perceptivo”.
“Nuestra área de enfoque se centra en los problemas tradicionales de comprensión del video, como la búsqueda semántica en archivos de gran tamaño o la clasificación, el chat de video, incluso los agentes de video y la generación aumentada por recuperación (RAG)”, afirma Lee. “Si tiene muchos datos de video y necesita poder buscar cosas con rapidez, la API de Twelve Labs le permite hacerlo en cuestión de minutos”. En la actualidad, más de 30 000 desarrolladores y empresas utilizan los modelos de Twelve Labs, incluidas marcas influyentes como la NFL.
Generación de información fotograma por fotograma
Twelve Labs ofrece dos modelos: Marengo y Pegasus. “Marengo se dedica a generar incrustaciones de video multimodales de gran calidad que permiten potenciar cualquier tipo de recuperación, ya sean imágenes, audio, video y texto”, dice Lee. “Pegasus es nuestro modelo de lenguaje de video, que puede combinar las peticiones del usuario y las incrustaciones que Marengo genera para responder a las preguntas de los usuarios, generar informes y mucho más”.
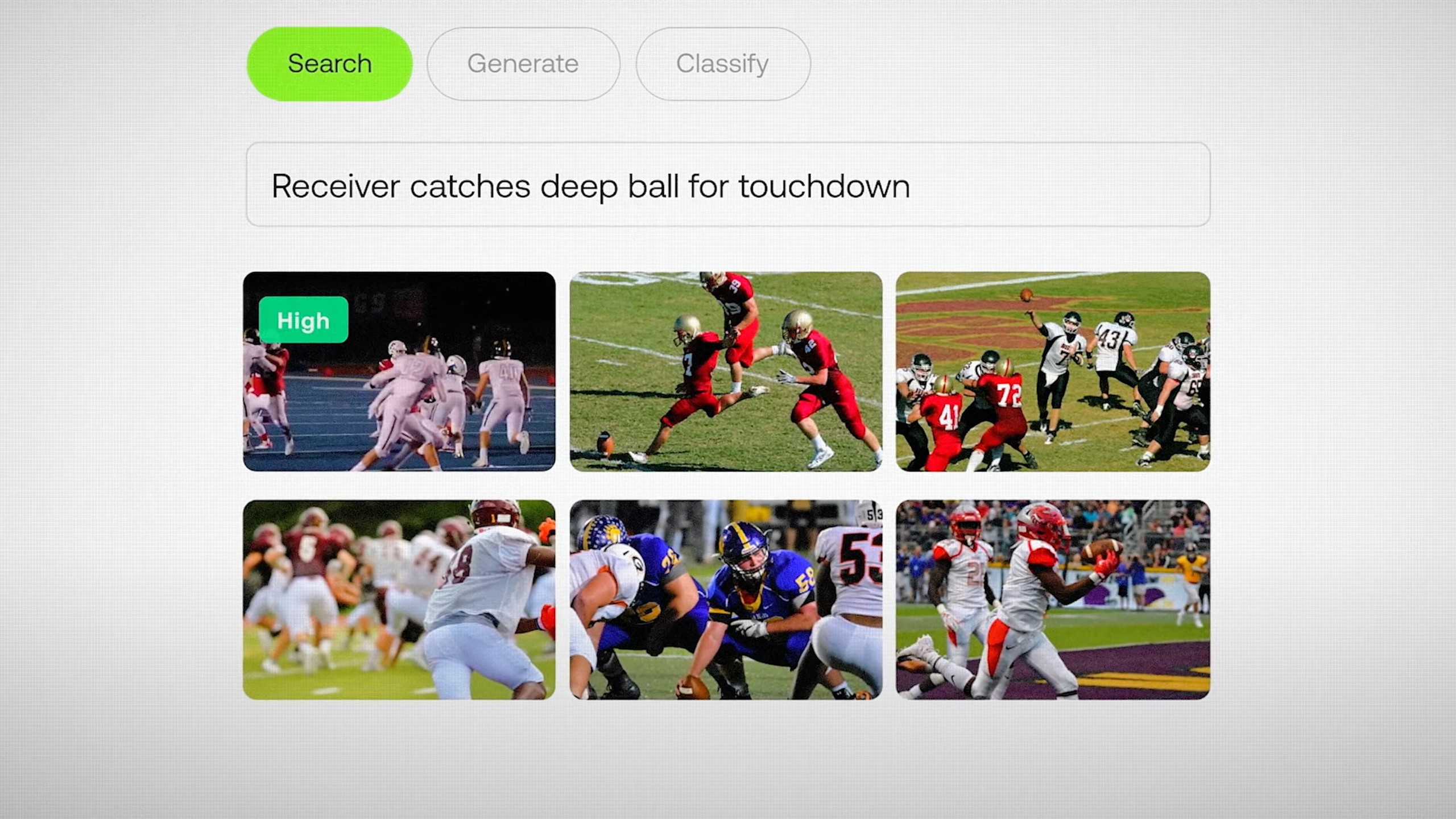
“Hacemos muchas investigaciones novedosas sobre modelos de arquitectura que son más adecuados para el video. Hay muchos modelos de incrustación de texto e imágenes, pero el video es algo completamente diferente. Esa es la vertiente de la investigación, pero aún queda por hacer el trabajo de ingeniería más importante”, señala Lee.
Afortunadamente, las startups de IA están acostumbradas a abordar importantes desafíos técnicos y Twelve Labs no es diferente. “En la práctica, el 80 por ciento de los datos del mundo son videos, lo que equivale a más de 100 zettabytes de contenido de video que utilizamos primero para el entrenamiento y luego para la indexación y la comprensión”, afirma Lee. “El desafío aquí es la enorme escala”. Twelve Labs trabaja con AWS para superar ese desafío con el acceso a la tecnología y la experiencia necesarias para alcanzar sus objetivos.
Impulso del razonamiento perceptivo con tecnología innovadora
Twelve Labs utiliza Amazon SageMaker HyperPod para entrenar y escalar sus modelos de manera más eficiente. Las empresas utilizan SageMaker HyperPod para entrenar a los FM durante semanas o incluso meses y, al mismo tiempo, supervisar de forma activa el estado de los clústeres y aprovechar la resiliencia de los nodos y los trabajos automatizados. Si se detecta un nodo con errores, se reemplaza automáticamente y se reanuda el entrenamiento de los modelos, lo que permite ahorrar hasta un 40 por ciento del tiempo de entrenamiento.
“Una de las cosas más difíciles de crear estos modelos es que trabajamos con máquinas realmente potentes a una escala increíble, desde cientos de GPU hasta decenas de miles de CPU”, comenta Lee. “A pesar de que estas máquinas están muy bien fabricadas y son robustas, hay muchos fallos de hardware y nodos”.
“Trabajamos en estrecha colaboración con el equipo de SageMaker HyperPod. Aprovechamos la resiliencia y la infraestructura de entrenamiento distribuida que AWS creó, lo que nos permite poner en marcha las GPU, entrenar nuestros modelos lo antes posible y distribuirlos”, dice Lee. “La resiliencia de SageMaker HyperPod, la capacidad de reparar los nodos muertos y, básicamente, subcontratar la computación de alto rendimiento nos resultaron muy atractivas”.
El equipo de Twelve Labs también aprovecha AWS Elemental MediaConvert para la transcodificación de video basada en la nube, lo que elimina la necesidad de mantener la infraestructura de procesamiento de video. “La infraestructura de streaming de AWS Elemental MediaConvert nos permite centrarnos en lo que somos realmente buenos”, confiesa Lee.
Twelve Labs también ofrece una integración profunda con Amazon Simple Storage Service (Amazon S3), un servicio de almacenamiento de objetos que proporciona escalabilidad, disponibilidad de datos, seguridad y rendimiento líderes en el sector. “Nuestros clientes realmente disfrutan de la perfecta integración de los flujos de trabajo de Twelve Labs y S3”, señala Lee. “Si almacena la gran mayoría de sus datos en S3, podemos extraer sin problemas sus datos de video, indexarlos, incrustarlos y posibilitar búsquedas sin problemas”.
Enfoque en el crecimiento
AWS también ayudó a Twelve Labs a impulsar su crecimiento a través de AWS Activate, un programa emblemático que proporciona créditos en la nube, asistencia técnica y tutoría empresarial para startups. El equipo de Startups de AWS está formado por fundadores, creadores y visionarios que no solo comprenden los desafíos que supone la creación de startups, sino que además vivieron esa experiencia y tienen la experiencia necesaria para ayudar a otros a lo largo de su proceso. Esto incluye encontrar los servicios de AWS adecuados para su caso de uso, financiar una prueba de concepto inicial y mucho más.
Una parte clave de AWS Activate es ayudar a las startups a desarrollar estrategias de comercialización y aumentar la exposición a nuevos clientes. Como parte de ese proceso, Twelve Labs se unió a AWS Marketplace, una tienda digital seleccionada que permite a la empresa ofrecer sin problemas sus servicios de inteligencia de video a una base de clientes global. Las empresas de todos los tamaños ahora pueden usar AWS Marketplace para buscar, probar, comprar, implementar y administrar rápidamente los productos de Twelve Labs.
Una IA que ve el mundo como nosotros
En el futuro, Twelve Labs seguirá colaborando con AWS y abriendo nuevos caminos en la inteligencia de video con tecnología de IA. “La razón más convincente para entusiasmarnos por trabajar con AWS es la empatía que compartimos con nuestros clientes, que manejan petabytes (o incluso exabytes) de datos de video”, dice Lee.
“AWS nos brindó la potencia de computación y la asistencia necesarias para resolver los desafíos de la IA multimodal y hacer que el video sea más accesible, y esperamos tener una colaboración fructífera en los próximos años a medida que continuamos con nuestra innovación y nos expandimos a nivel mundial”, afirma Lee. “Podemos acelerar el entrenamiento de nuestros modelos, ofrecer nuestra solución de forma segura a miles de desarrolladores de todo el mundo y controlar los costos de computación, al mismo tiempo que superamos los límites de la comprensión y la creación de video mediante IA generativa”.
Como parte de un Acuerdo de colaboración estratégica (SCA) de tres años, la empresa ahora trabaja con AWS para mejorar aún más sus capacidades de entrenamiento de modelos e implementar sus modelos en nuevos sectores, como la salud y la fabricación. “Queremos ser la corteza visual de todos los futuros agentes de IA, agentes que necesitan ver el mundo de la manera en que lo vemos nosotros”, señala Lee.
¿Qué le pareció este contenido?