AWS Machine Learning Blog
Category: Amazon SageMaker

Enabling production-grade generative AI: New capabilities lower costs, streamline production, and boost security
As generative AI moves from proofs of concept (POCs) to production, we’re seeing a massive shift in how businesses and consumers interact with data, information—and each other. In what we consider “Act 1” of the generative AI story, we saw previously unimaginable amounts of data and compute create models that showcase the power of generative […]

Scaling Thomson Reuters’ language model research with Amazon SageMaker HyperPod
In this post, we explore the journey that Thomson Reuters took to enable cutting-edge research in training domain-adapted large language models (LLMs) using Amazon SageMaker HyperPod, an Amazon Web Services (AWS) feature focused on providing purpose-built infrastructure for distributed training at scale.

Introducing Amazon EKS support in Amazon SageMaker HyperPod
This post is designed for Kubernetes cluster administrators and ML scientists, providing an overview of the key features that SageMaker HyperPod introduces to facilitate large-scale model training on an EKS cluster.

Anomaly detection in streaming time series data with online learning using Amazon Managed Service for Apache Flink
In this post, we demonstrate how to build a robust real-time anomaly detection solution for streaming time series data using Amazon Managed Service for Apache Flink and other AWS managed services.

Optimizing MLOps for Sustainability
In this post, we review the guidance for optimizing MLOps for Sustainability on AWS, providing service-specific practices to understand and reduce the environmental impact of these workloads.

Genomics England uses Amazon SageMaker to predict cancer subtypes and patient survival from multi-modal data
In this post, we detail our collaboration in creating two proof of concept (PoC) exercises around multi-modal machine learning for survival analysis and cancer sub-typing, using genomic (gene expression, mutation and copy number variant data) and imaging (histopathology slides) data. We provide insights on interpretability, robustness, and best practices of architecting complex ML workflows on AWS with Amazon SageMaker. These multi-modal pipelines are being used on the Genomics England cancer cohort to enhance our understanding of cancer biomarkers and biology.
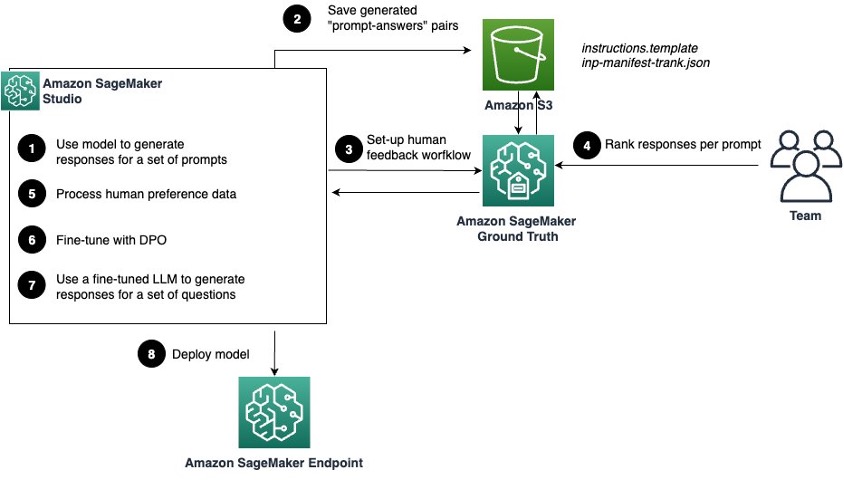
Align Meta Llama 3 to human preferences with DPO, Amazon SageMaker Studio, and Amazon SageMaker Ground Truth
In this post, we show you how to enhance the performance of Meta Llama 3 8B Instruct by fine-tuning it using direct preference optimization (DPO) on data collected with SageMaker Ground Truth.

Fine-tune Llama 3 for text generation on Amazon SageMaker JumpStart
In this post, we demonstrate how to fine-tune the recently released Llama 3 models from Meta, specifically the llama-3-8b and llama-3-70b variants, using Amazon SageMaker JumpStart.

Ground truth curation and metric interpretation best practices for evaluating generative AI question answering using FMEval
In this post, we discuss best practices for working with Foundation Model Evaluations Library (FMEval) in ground truth curation and metric interpretation for evaluating question answering applications for factual knowledge and quality.

Deploy Amazon SageMaker pipelines using AWS Controllers for Kubernetes
In this post, we show how ML engineers familiar with Jupyter notebooks and SageMaker environments can efficiently work with DevOps engineers familiar with Kubernetes and related tools to design and maintain an ML pipeline with the right infrastructure for their organization. This enables DevOps engineers to manage all the steps of the ML lifecycle with the same set of tools and environment they are used to.