AWS Big Data Blog
Category: Serverless

Ingest Salesforce data into Amazon S3 using the CData JDBC custom connector with AWS Glue
Organizations that successfully generate business value from their data will outperform their peers. Many AWS customers require a data storage and analytics solution that combines the prospect information stored in Salesforce, a popular and widely used customer relationship management (CRM) platform, with other structured and unstructured data in their data lake to innovate and build […]

Integrating Datadog data with AWS using Amazon AppFlow for intelligent monitoring
Infrastructure and operation teams are often challenged with getting a full view into their IT environments to do monitoring and troubleshooting. New monitoring technologies are needed to provide an integrated view of all components of an IT infrastructure and application system. Datadog provides intelligent application and service monitoring by bringing together data from servers, databases, […]

Performing data transformations using Snowflake and AWS Glue
May 2022: This post was reviewed for accuracy. In the connected world, data is getting generated from many different sources in a wide variety of data formats. Enterprises are looking for tools to ingest from these evolving data sources as well as programmatically customize the ingested data to meet their data analytics needs. You also need […]
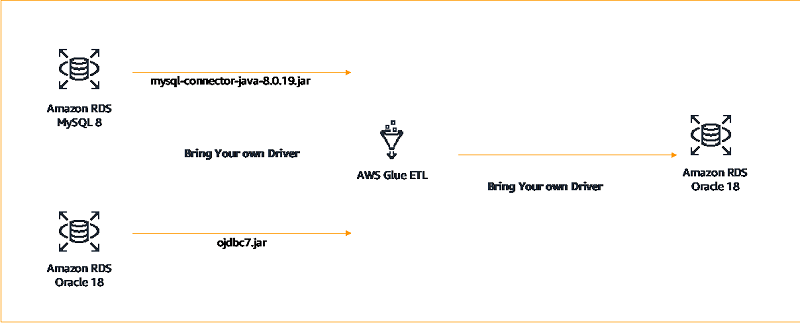
Building AWS Glue Spark ETL jobs by bringing your own JDBC drivers for Amazon RDS
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. AWS Glue has native connectors to connect to supported data sources either on AWS or elsewhere using JDBC drivers. Additionally, AWS Glue now enables you to bring your own JDBC drivers […]

Developing, testing, and deploying custom connectors for your data stores with AWS Glue
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue already integrates with various popular data stores such as the Amazon Redshift, RDS, MongoDB, and Amazon S3. Organizations continue to evolve and use a variety of data stores that best fit […]

Migrating data from Google BigQuery to Amazon S3 using AWS Glue custom connectors
July, 2022: This post was reviewed and updated to include a mew data point on the effective runtime with the latest version, explaining Glue 3,0 and autoscaling. October, 2024: In Glue 4.0 we have introduced a native and managed connector for Google BigQuery. You can follow the instruction in the blog postUnlock scalable analytics with […]

Building AWS Glue Spark ETL jobs using Amazon DocumentDB (with MongoDB compatibility) and MongoDB
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. AWS Glue has native connectors to connect to supported data sources on AWS or elsewhere using JDBC drivers. Additionally, AWS Glue now supports reading and writing to Amazon DocumentDB (with MongoDB […]

Writing to Apache Hudi tables using AWS Glue Custom Connector
December 2022: This post was reviewed for accuracy. In today’s world, most organizations have to tackle the 3 V’s of variety, volume and velocity of big data. In this blog post, we talk about dealing with the variety and volume aspects of big data. The challenge of dealing with the variety involves processing data from […]
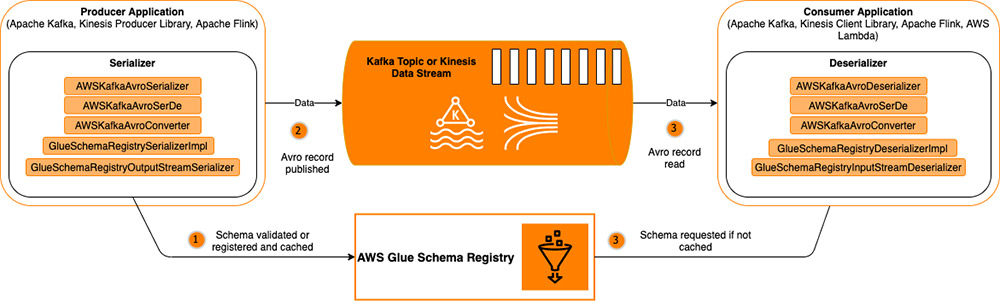
Validate, evolve, and control schemas in Amazon MSK and Amazon Kinesis Data Streams with AWS Glue Schema Registry
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Data streaming technologies like Apache Kafka and Amazon Kinesis Data Streams capture and distribute data generated by thousands or millions of applications, websites, or machines. These technologies […]

Building complex workflows with Amazon MWAA, AWS Step Functions, AWS Glue, and Amazon EMR
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a fully managed service that makes it easy to run open-source versions of Apache Airflow on AWS and build workflows to run your extract, transform, and load (ETL) jobs and data pipelines. You can use AWS Step Functions as a serverless function orchestrator to build scalable […]