AWS Big Data Blog
Category: Serverless

Introducing AWS Glue 3.0 with optimized Apache Spark 3.1 runtime for faster data integration
May 2022: This post was reviewed for accuracy. In August 2020, we announced the availability of AWS Glue 2.0. AWS Glue 2.0 reduced job startup times by 10x, enabling customers to realize an average of 45% cost savings on their extract, transform, and load (ETL) jobs. The fast start time allows customers to easily adopt […]

Build a serverless event-driven workflow with AWS Glue and Amazon EventBridge
April 2025: This post was reviewed for accuracy. Customers are adopting event-driven-architectures to improve the agility and resiliency of their applications. As a result, data engineers are increasingly looking for simple-to-use yet powerful and feature-rich data processing tools to build pipelines that enrich data, move data in and out of their data lake and data […]

Design a data mesh architecture using AWS Lake Formation and AWS Glue
April 2024: This post was reviewed for accuracy. Organizations of all sizes have recognized that data is one of the key enablers to increase and sustain innovation, and drive value for their customers and business units. They are eagerly modernizing traditional data platforms with cloud-native technologies that are highly scalable, feature-rich, and cost-effective. As you […]

Automate Amazon ES synonym file updates
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Search engines provide the means to retrieve relevant content from a collection of content. However, this can be challenging if certain exact words aren’t entered. You need to find the right item from a catalog of products, or the correct […]
Improve query performance using AWS Glue partition indexes
While creating data lakes on the cloud, the data catalog is crucial to centralize metadata and make the data visible, searchable, and queryable for users. With the recent exponential growth of data volume, it becomes much more important to optimize data layout and maintain the metadata on cloud storage to keep the value of data […]

Build a data quality score card using AWS Glue DataBrew, Amazon Athena, and Amazon QuickSight
Data quality plays an important role while building an extract, transform, and load (ETL) pipeline for sending data to downstream analytical applications and machine learning (ML) models. The analogy “garbage in, garbage out” is apt at describing why it’s important to filter out bad data before further processing. Continuously monitoring data quality and comparing it […]

Simplify incoming data ingestion with dynamic parameterized datasets in AWS Glue DataBrew
When data analysts and data scientists prepare data for analysis, they often rely on periodically generated data produced by upstream services, such as labeling datasets from Amazon SageMaker Ground Truth or Cost and Usage Reports from AWS Billing and Cost Management. Alternatively, they can regularly upload such data to Amazon Simple Storage Service (Amazon S3) […]

Set up CI/CD pipelines for AWS Glue DataBrew using AWS Developer Tools
An integral part of DevOps is adopting the culture of continuous integration and continuous delivery (CI/CD). This enables teams to securely store and version code, maintain parity between development and production environments, and achieve end-to-end automation of the release cycle, including building, testing, and deploying to production. In essence, development teams follow CI/CD processes to […]

How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform
April 2024: This post was reviewed for accuracy. This is a joint blog post co-authored with Anu Jain, Graham Person, and Paul Conroy from JP Morgan Chase. Most modern organizations recognize that their data benefits their entire enterprise. Data has value to the individual business process that produces it, but data’s additional potential can be […]
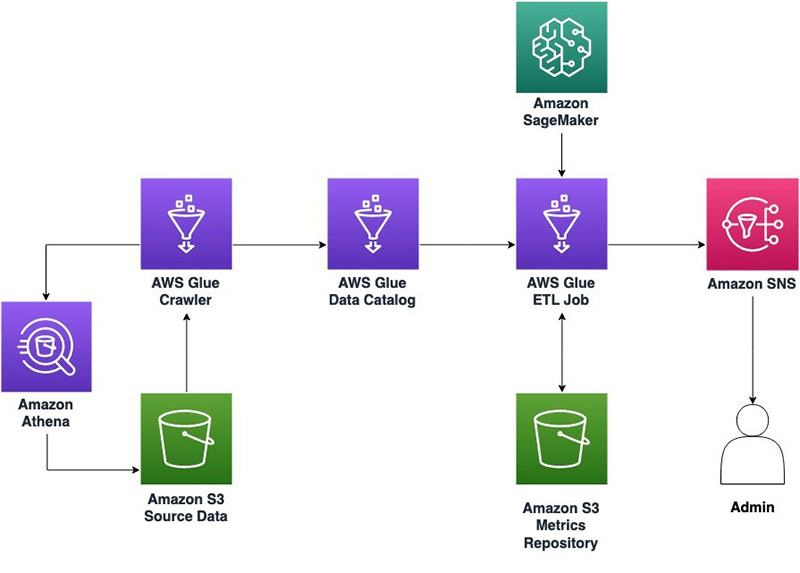
Monitor data quality in your data lake using PyDeequ and AWS Glue
August 2024: This post was reviewed and updated with examples against a new dataset. Additionally, changed the architecture to use AWS Glue Studio Notebooks and added information on the appropriate Deequ/PyDeequ versions. In our previous post, we introduced PyDeequ, an open-source Python wrapper over Deequ, which enables you to write unit tests on your data […]