AWS Big Data Blog
Category: Database

Apply record level changes from relational databases to Amazon S3 data lake using Apache Hudi on Amazon EMR and AWS Database Migration Service
Data lakes give organizations the ability to harness data from multiple sources in less time. Users across different roles are now empowered to collaborate and analyze data in different ways, leading to better, faster decision-making. Amazon Simple Storage Service (Amazon S3) is the highly performant object storage service for structured and unstructured data and the […]

Get started with Amazon Redshift cross-database queries (preview)
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL, business intelligence (BI), and reporting tools. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day and power analytics […]

Migrating IBM Netezza to Amazon Redshift using the AWS Schema Conversion Tool
The post How to migrate a large data warehouse from IBM Netezza to Amazon Redshift with no downtime described a high-level strategy to move from an on-premises Netezza data warehouse to Amazon Redshift. In this post, we explain how a large European Enterprise customer implemented a Netezza migration strategy spanning multiple environments, using the AWS […]

Federating Amazon Redshift access from OneLogin
December 2022: This post was reviewed and updated for accuracy. You can use federation to access AWS accounts using credentials from a corporate directory, utilizing open standards such as SAML, to exchange identity and security information between an identity provider (IdP) and an application. With this integration, you manage user identities to AWS resources centrally […]

Automating deployment of Amazon Redshift ETL jobs with AWS CodeBuild, AWS Batch, and DBT
This post was last reviewed and updated June, 2022 to update the code and service used on the AWS CloudFormation template. Data has become an essential part of every business, and its volume, velocity, and variety continue to increase. This has resulted in more complex ETL jobs with interdependencies between each other. There is also […]
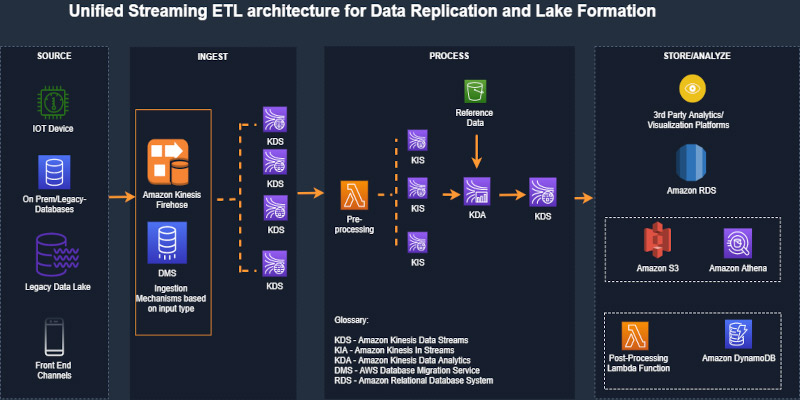
Unified serverless streaming ETL architecture with Amazon Kinesis Data Analytics
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Businesses across the world […]

Federating single sign-on access to your Amazon Redshift cluster with PingIdentity
Single sign-on (SSO) enables users to have a seamless user experience while accessing various applications in the organization. If you’re responsible for setting up security and database access privileges for users and tasked with enabling SSO for Amazon Redshift, you can set up SSO authentication using ADFS, PingIdentity, Okta, Azure AD or other SAML browser […]

Best practices using AWS SCT and AWS Snowball to migrate from Teradata to Amazon Redshift
This is a guest post from ZS. In their own words, “ZS is a professional services firm that works closely with companies to help develop and deliver products and solutions that drive customer value and company results. ZS engagements involve a blend of technology, consulting, analytics, and operations, and are targeted toward improving the commercial […]
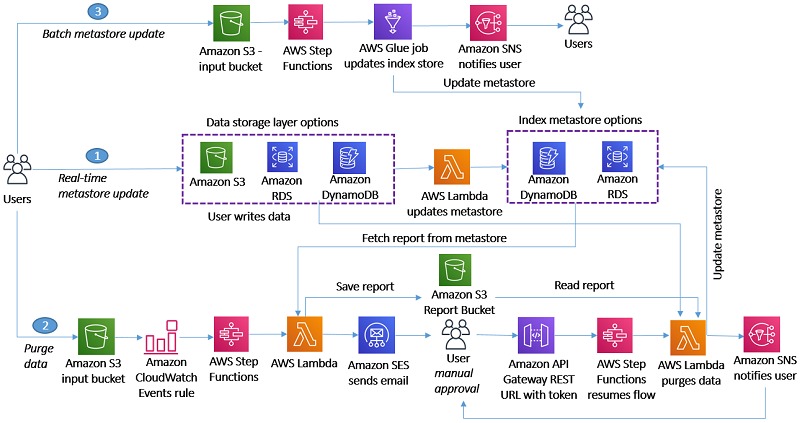
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]

Stream CDC into an Amazon S3 data lake in Parquet format with AWS DMS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Most organizations generate data in real time and ever-increasing volumes. Data is captured from a variety of sources, such as transactional and reporting databases, application logs, customer-facing websites, and external feeds. Companies […]