AWS Big Data Blog
Category: AWS Glue
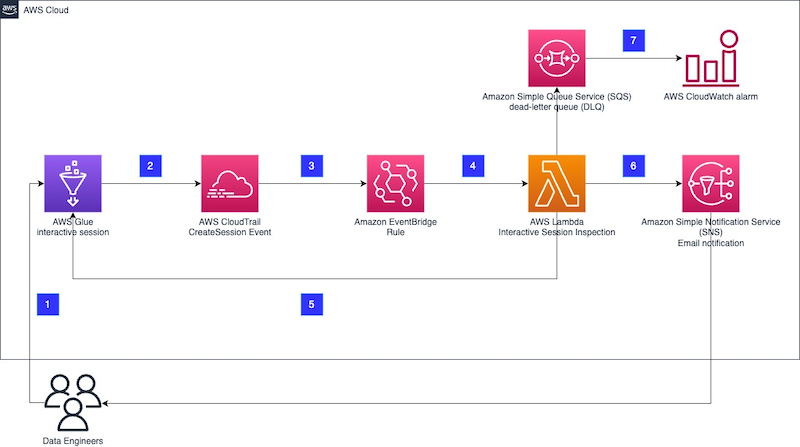
Enforce boundaries on AWS Glue interactive sessions
AWS Glue interactive sessions allow engineers to build, test, and run data preparation and analytics workloads in an interactive notebook. Interactive sessions provide isolated development environments, take care of the underlying compute cluster, and allow for configuration to stop idling resources. Glue interactive sessions provides default recommended configurations, and also allows users to customize the […]

Get started managing partitions for Amazon S3 tables backed by the AWS Glue Data Catalog
Large organizations processing huge volumes of data usually store it in Amazon Simple Storage Service (Amazon S3) and query the data to make data-driven business decisions using distributed analytics engines such as Amazon Athena. If you simply run queries without considering the optimal data layout on Amazon S3, it results in a high volume of […]

Build an Amazon Redshift data warehouse using an Amazon DynamoDB single-table design
Amazon DynamoDB is a fully managed NoSQL service that delivers single-digit millisecond performance at any scale. It’s used by thousands of customers for mission-critical workloads. Typical use cases for DynamoDB are an ecommerce application handling a high volume of transactions, or a gaming application that needs to maintain scorecards for players and games. In traditional […]

Efficiently crawl your data lake and improve data access with an AWS Glue crawler using partition indexes
In today’s world, customers manage vast amounts of data in their Amazon Simple Storage Service (Amazon S3) data lakes, which requires convoluted data pipelines to continuously understand the changes in the data layout and make them available to consuming systems. AWS Glue crawlers provide a straightforward way to catalog data in the AWS Glue Data […]

AWS Glue streaming application to process Amazon MSK data using AWS Glue Schema Registry
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time data analytics, considering the growing velocity and volume of data being collected. This data can come from a diverse range of sources, including Internet of Things (IoT) devices, user applications, and logging and telemetry information from applications, […]

How Cargotec uses metadata replication to enable cross-account data sharing
This is a guest blog post co-written with Sumesh M R from Cargotec and Tero Karttunen from Knowit Finland. Cargotec (Nasdaq Helsinki: CGCBV) is a Finnish company that specializes in cargo handling solutions and services. They are headquartered in Helsinki, Finland, and operates globally in over 100 countries. With its leading cargo handling solutions and […]

AWS Glue Data Quality is Generally Available
We are excited to announce the General Availability of AWS Glue Data Quality. Our journey started by working backward from our customers who create, manage, and operate data lakes and data warehouses for analytics and machine learning. To make confident business decisions, the underlying data needs to be accurate and recent. Otherwise, data consumers lose […]

Visualize data quality scores and metrics generated by AWS Glue Data Quality
AWS Glue Data Quality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug data quality issues. AWS Glue Data Quality generates a substantial amount of operational runtime information during […]

Set up alerts and orchestrate data quality rules with AWS Glue Data Quality
Alerts and notifications play a crucial role in maintaining data quality because they facilitate prompt and efficient responses to any data quality issues that may arise within a dataset. By establishing and configuring alerts and notifications, you can actively monitor data quality and receive timely alerts when data quality issues are identified. This proactive approach […]

Set up advanced rules to validate quality of multiple datasets with AWS Glue Data Quality
Data is the lifeblood of modern businesses. In today’s data-driven world, companies rely on data to make informed decisions, gain a competitive edge, and provide exceptional customer experiences. However, not all data is created equal. Poor-quality data can lead to incorrect insights, bad decisions, and lost opportunities. AWS Glue Data Quality measures and monitors the […]