亚马逊AWS官方博客
深度剖析 – 基于亚马逊云科技使用 Apache DolphinScheduler 进行数据任务调度
 |
背景介绍
Apache DolphinScheduler 是一个分布式、可扩展的开源工作流编排平台,拥有强大的 DAG 可视化界面。DolphinScheduler 在设计上充分考虑了用户对于调度服务的需求,具有以下优势:
易于使用:DolphinScheduler 提供了一个直观的 WebUI,使用户能够方便地进行任务定义、调度配置以及监控管理等操作。无需编写复杂的脚本或代码即可创建复杂的工作流。
高可用性及可扩展性:采用主从架构(Master-Worker),支持多 Master 和多 Worker 模式,保证了系统的高可用性和稳定性。支持动态增加或减少 Worker 节点,以应对不同规模的任务负载。同时,系统提供了丰富的插件机制,便于用户根据需要定制功能。
多种任务类型支持:除了支持 Shell、Python 等脚本任务外,还支持 Spark、Flink、Hive 等多种大数据处理框架的任务调度,满足不同场景下的需求。目前 DolphinScheduler 已经原生集成了亚马逊云科技的大部分数据服务,如 EMR、Redshift、DMS、DataSync、Athena、S3。
支持告警机制:内置告警模块,能够在任务失败或其他异常情况下及时通知用户,保证问题能够被迅速发现和解决。
安全与权限控制:提供细粒度的权限管理和认证机制,确保敏感信息的安全。
本文将详细介绍 DolphinScheduler 的云原生容器化部署 Amazon EKS。详细解释如何结合亚马逊云科技的任务插件、数据源插件、存储插件的集成。帮助更高效的使用 DolphinScheduler 进行云服务调用。
极速部署 – DolphinScheduler on EKS
DolphinScheduler 3.2.2 版本于 2024 年 7 月 23 号正式发布,您可以通过查阅官方文档来深入了解 DolphinScheduler 的架构和技术细节。本文重点介绍如何基于亚马逊云科技使用 Terraform 脚本快速部署 DolphinScheduler 的生产可用环境。
部署脚本的核心架构细节:
EKS 架构:部署基于 EKS 容器化,部署完成后会提供一个公开可访问的 ELB 代理域名进行用户访问。
 |
部署用于 DolphinScheduler 的核心服务组件(全部由 Terraform 脚本进行部署):
- Serverless 数据库:采用 Amazon Aurora Serverless v2,支持弹性伸缩范围配置,默认范围为 2-16 ACUs,为系统提供弹性数据库能力。
- 持久化存储:使用Amazon EFS 提供无服务器、弹性的持久化存储。
- 任务日志:默认启用远程任务日志存储,日志保存在 Amazon S3 中,支持任务级别日志的审阅。
- 依赖和文件管理:依赖项和文件管理存储在 S3 中。
- 命名空间管理:DolphinScheduler 的命名空间和节点扩展由 Karpenter 自动管理。
以下详细说明如何快速进行 DolphinScheduler 部署。
基础环境准备
- 进入亚马逊云科技 Console,创建 EC2 虚拟机进行部署准备(以 Amazon linux 2023 为例)

- 进行部署前的环境准备
安装 terraform
参考:https://developer.hashicorp.com/terraform/install#
安装 helm
参考:https://docs.aws.amazon.com/zh_cn/eks/latest/userguide/helm.html
安装 kubectl EKS(版本 1.30)
参考:https://docs.aws.amazon.com/zh_cn/eks/latest/userguide/install-kubectl.html
安装部署
- 下载部署源码并执行部署脚本:
等待执行完成 大约 30-50 分钟
 |
即刻体验
执行输出的 kubectl 配置命令
 |
获取 DolphinScheduler 访问地址
访问地址为:xxx.elb.amazonaws.com:12345/dolphinscheduler
 |
深度使用 – DolphinScheduler 云插件
任务插件 – Amazon EMR
Amazon EMR 提供了两种常用的 API 操作来管理和执行计算任务:RunJobFlow 和 AddJobFlowSteps。
| 操作 | 主要用途 | 典型流程 | |
| 1 | RunJobFlow | 创建新集群并提交初始任务 | 提交 RunJobFlowRequest,配置集群参数和初始 Steps,启动集群执行任务 |
| 2 | AddJobFlowSteps | 向已存在集群追加新任务 | 提交 AddJobFlowStepsRequest,指定 JobFlowId 和 Steps,追加任务 |
而 DolphinScheduler 中的 Amazon EMR 任务类型同时提供了上述两种 EMR API 的支持。接下来,将以 SparkPi 为例,演示如何在 DolphinScheduler 中,分别使用上述两种 API 提交 EMR 任务。
1. 创建 EMR 集群并提交任务:RUN_JOB_FLOW
在 dolphinscheduler 的工作流定义中,选择 EMR 任务类型,创建任务节点,并在节点详细中配置程序类型为:RUN_JOB_FLOW,然后设置 jobFlowDefineJson。
 |
详细的 json 样例如下所示。
在 DolphinScheduler 上运行上述工作流后,转到亚马逊云科技 Console上查看,就可以看到一个名叫“SparkPi”的群集正在被创建。
 |
当集群创建完成后,会看到 “Steps” 选项卡中增加了一个 Step。当该 Step 执行完成后,集群就会自动终止。
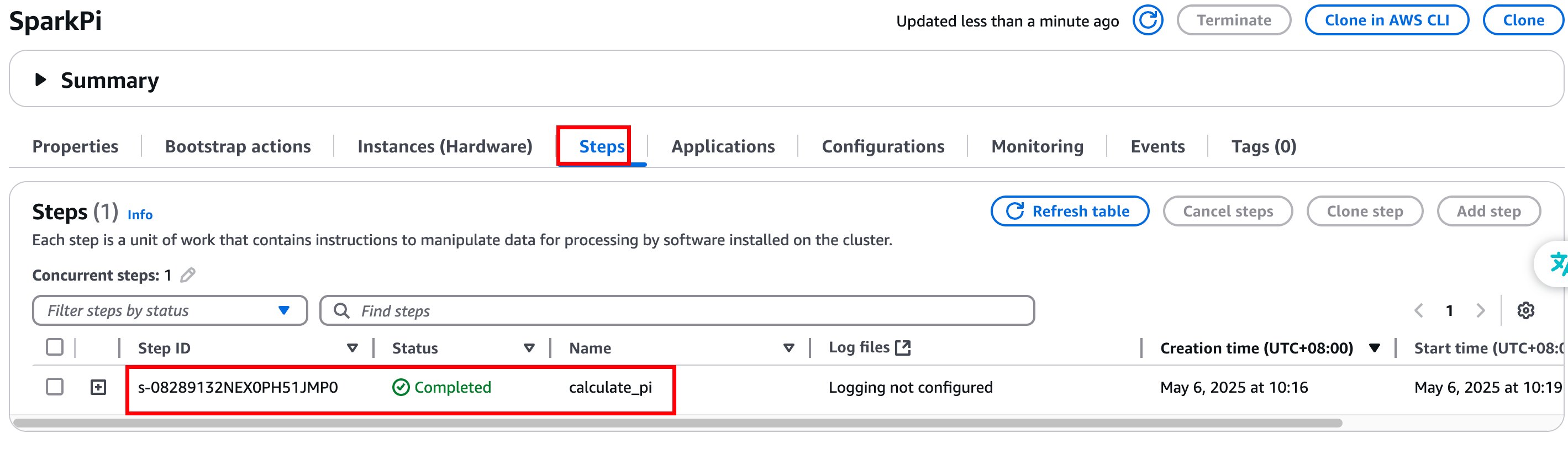 |
2. 向现有 EMR 集群提交任务:ADD_JOB_FLOW_STEPS
如果要向一个已有的 EMR 集群提交任务,可以在 DolphinScheduler 的 EMR 任务节点中,选择程序类型为:ADD_JOB_FLOW_STEPS。同时在“stepsDefineJson”中填写任务定义。
 |
详细的 “stepsDefineJson”如下所示。
上述 Json 中的 JobFlowId,需要填写 Amazon EMR 集群的 ID,如下图所示。
 |
在 DolphinScheduler 上运行上述工作流后,转到亚马逊云科技 Console 上查看,就可以看到现有的 EMR 集群的“Steps”选项卡中增加了一个 Step,正在运行。
 |
任务插件 – Amazon DMS
DMS(Database Migration Service):是一种帮助用户轻松迁移数据库到亚马逊云的服务,支持多种数据库源和目标,确保数据迁移过程的高效与安全。使用如下步骤可以在 DolphinScheduler 调度 DMS 的数据同步任务。
1. 创建数据源和目的端 Endpoints
 |
2. 配置 DolphinScheduler 任务
 |
3. 启动任务运行,可以查看亚马逊云科技控制台上,DMS 任务被正确创建并运行
 |
查看 DolphinScheduler 日志,任务运行
 |
 |
任务插件 – Amazon DataSync
DataSync:是一项用于在本地存储和亚马逊云科技之间快速、安全地传输大量数据的服务,简化了数据迁移、归档及分析的过程。使用如下步骤可以在 DolphinScheduler 调度 DataSync 的数据同步任务。
1. 创建 DataSync 服务中的源和目的端位置记录(以 S3 为例)
 |
2. 创建 DolphinScheduler 任务
 |
3. 执行任务,查看 Datasync 控制台任务被成功创建及运行
 |
 |
数据源插件 – Amazon Athena
Athena:是一个交互式查询服务,允许使用标准 SQL 直接从 Amazon S3 中查询数据,无需构建或维护额外的数据仓库架构。
1. DolphinScheduler 没有直接集成 Athena 驱动程序,需要下载 AthenaJDBC42.jar 到 worker 节点,并重启服务
2. 在数据源页面新建 Athena 数据源,填写
 |
 |
3. 在工作流中定义任务,运行后可查看到执行日志
 |
数据源插件 – Amazon Redshift
Redshift:是亚马逊云科技提供的完全托管的数据仓库服务,能够以快速且经济高效的方式运行复杂的数据查询,适用于大规模数据分析工作。
1. 将驱动 jar 放到服务的 libs 目录下,重启 ds 服务
 |
2. 在数据源页面新建 Redshift 数据源,填写 ip、端口、用户名等信息;点击测试连接验证可联通性
 |
3. 编辑任务及 query SQL
 |
 |
 |
4. 点击工作流实例进入 DAG 页面在任务节点右键,点击查看任务日志
 |
 |
存储插件 – Amazon S3
1. 修改配置文件存储类型为 S3,填充 accessKey、bucket、region 等信息
 |
2. 启动 ds 服务,在资源中心新建文件夹 test;进入 test,新建文件 test.sh
 |
3. 检查 S3 存储桶,生成了对应的资源文件
 |
4. 新建工作流,新建 Shell 任务节点,在资源那里引用刚创建的资源文件 test/test.sh,保存工作流;运行工作流,即可在 shell 任务引用到资源中心 S3 的文件
 |