亚马逊AWS官方博客
利用 Amazon Bedrock 构建高效 SEO 内容生成系统:从流量挖掘到智能创作
 |
前言
在当今数字营销环境中,有机搜索流量是企业获取潜在客户的最具成本效益的渠道之一。然而,许多企业在 SEO 实践中面临共同挑战:专业人才短缺、前期投入大、实施复杂且见效周期长。这些因素导致 SEO 策略常被搁置,错失了宝贵的流量机会。
本文将详细介绍如何利用 Amazon Bedrock 生成式 AI 服务构建一套高效、低成本的 SEO 解决方案。我们将遵循搜索引擎的核心原则——为用户提供真正有价值的内容。从关键词挖掘、搜索意图分析到内容智能创作,本文将为您展示一个完整的、可实施的 SEO 内容生成流程。
SEO 流程概述
接下来将分步骤展示 Amazon Bedrock 生成式 AI 赋能 SEO 的实战方法论。我们会深入剖析每个环节的技术细节和最佳实践,包括:如何构建精准的关键词池、解读用户背后的搜索意图、智能匹配相关商品,以及如何指导 AI 生成既符合搜索引擎算法又满足用户需求的优质内容。通过这套系统,企业可以突破传统 SEO 的资源瓶颈,建立可持续增长的有机流量获取渠道。
一、流量挖掘
传统 SEO 流程通常依赖第三方平台查找竞争对手的关键词,虽然这种方法可以快速获取相关关键词,但这些关键词未必适合自身平台或产品特点。下面介绍一种基于 Amazon Bedrock 的低成本、高效率的流量挖掘方法,以电商产品为例:
首先,利用 Amazon Bedrock 的大模型从产品标题中提取有效关键词:
如产品标题是“Ekouaer Pajamas for Women Set Cute Pjs Soft Sleepwear Summer Sleeveless Tops and Shorts Travel Lounge Sets with Pockets”
As an SEO expert, please extract valid keywords from the following product titles. I will use these keywords to call the search engine API to obtain the real search keywords and return them in json format.
Product title:Ekouaer Pajamas for Women Set Cute Pjs Soft Sleepwear Summer Sleeveless Tops and Shorts Travel Lounge Sets with Pockets
The format of the returned json is
{
'keywords':[]
}
模型返回结果:
{
"keywords": [
"Pajamas for Women",
"Women Pajama Set",
"Sleepwear",
"Pjs",
"Cute Pajamas",
"Soft Sleepwear",
"Summer Pajamas",
"Sleeveless Pajamas",
"Pajama Tops",
"Pajama Shorts",
"Lounge Sets",
"Pajamas with Pockets",
"Travel Pajamas",
"Ekouaer Pajamas"
]
}
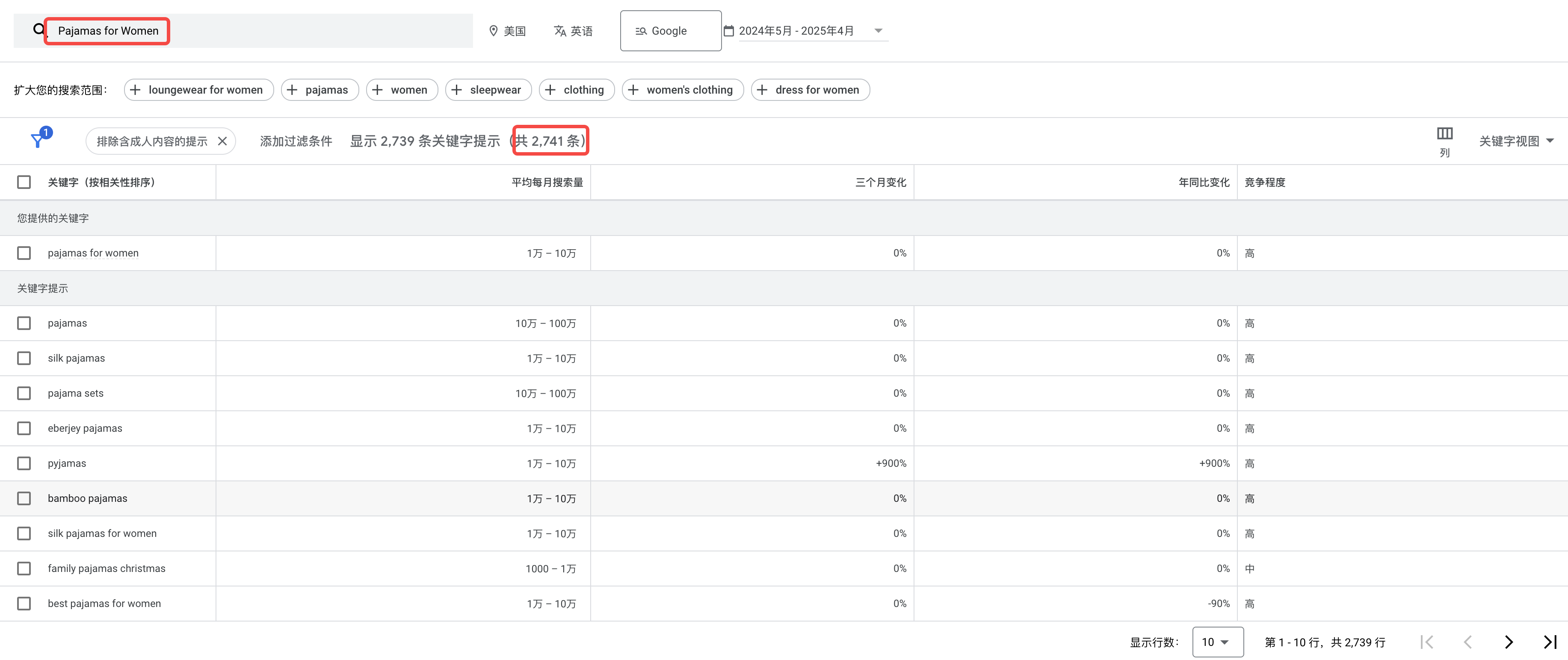
以”Pajamas for Women”为例,我们可以利用搜索引擎提供的 API(如 Google Keyword Planner)获取真实的搜索数据。在下图中,系统返回了 2741 条相关关键词数据,清晰展示了每个关键词的搜索量和竞争程度,帮助我们精准定位用户真正的搜索需求,为后续内容创作提供明确方向。
 |
二、精准流量筛选与搜索意图分析
获取流量机会后,需要进行有效筛选和搜索意图分析。由于搜索引擎对每个网站每天都有收录预算限制,我们需要优先创建最有价值的内容以快速获取流量。例如,可以优先考虑头部高流量关键词,如上图中的”pajama sets”,通过调用搜索引擎 API,分析返回的内容确定用户对此关键词的真实需求,如 Google 搜索引擎返回的是:
 |
接下来,利用 Amazon Bedrock 的大语言模型分析用户搜索意图,并生成针对性的内容主题:
As an SEO expert, for the keyword "pajama sets", the search engine returns the result
Search Results for 'pajama sets':{search results}
Please analyze the search intent and refer to the above information to create a new topic, because we will need to create content based on this topic and our products.
模型返回的主题建议:
{
"title": "Seasonal Comfort: The Ultimate Guide to Women's Pajama Sets for Every Occasion"
}
三、数据准备与向量化
为了创建真正有价值的 SEO 内容,我们需要将文章与相关商品自然结合。这就需要对商品数据进行向量化处理,利用语义相似性匹配主题与商品。
商品向量嵌入生成
首先,使用 Amazon Titan Embeddings 模型将商品信息转换为向量表示:
def get_titan_embedding(text):
"""使用Amazon Titan Embeddings模型获取文本嵌入向量"""
response = bedrock_runtime.invoke_model(
modelId='amazon.titan-embed-text-v1',
contentType='application/json',
accept='application/json',
body=json.dumps({"inputText": text})
)
response_body = json.loads(response['body'].read().decode())
embedding = response_body['embedding']
return embedding
商品数据结构化处理与向量化
将商品的多维信息整合为可向量化的文本,并确保向量与商品信息保持一致的对应关系:
# 创建用于存储所有向量和商品信息的列表
all_embeddings = []
all_product_info = []
# 处理每个商品
for item in product_items:
item_id = item['id']
asin = item['asin']
product_title = item['title']
about_product = item.get('about_product', '')
product_description = item.get('description', '')
# 创建用于生成嵌入的文本
text_for_embedding = f'product_title:{product_title}, about_product:{about_product}, product_description:{product_description}'
# 使用Amazon Titan Embeddings生成嵌入向量
embedding = get_titan_embedding(text_for_embedding)
# 按相同顺序添加到两个列表中,确保一一对应
all_embeddings.append(embedding)
all_product_info.append({
"id": item_id,
"asin": asin,
"product_title": product_title,
"about_product": about_product,
"product_description": product_description
# 其他商品属性...
})
向量数据持久化存储
将生成的向量数据和商品信息保存到 Amazon S3,同时保存索引映射关系,确保后续检索的准确性:
# 将向量数据保存为numpy数组
embeddings_array = np.array(all_embeddings, dtype=np.float32)
with io.BytesIO() as embeddings_buffer:
np.save(embeddings_buffer, embeddings_array)
embeddings_buffer.seek(0)
s3_client.upload_fileobj(embeddings_buffer, S3_BUCKET, f"{S3_PREFIX}product_embeddings.npy")
# 创建ID到索引的映射,确保后续能正确关联向量和商品
id_to_index = {product["id"]: i for i, product in enumerate(all_product_info)}
# 将商品信息和索引映射一起保存为JSON
product_data = {
"product_info": all_product_info,
"id_to_index": id_to_index
}
s3_client.put_object(
Body=json.dumps(product_data),
Bucket=S3_BUCKET,
Key=f"{S3_PREFIX}product_data.json"
)
高效向量检索系统
使用 FAISS(Facebook AI Similarity Search)构建高性能向量索引,实现快速相似商品检索,并利用索引映射确保返回正确的商品信息:
def build_faiss_index(embeddings):
"""构建FAISS索引"""
dimension = embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(embeddings)
return index
def search_similar_products(query_text, index, product_data, k=5):
"""搜索与查询文本相似的商品"""
product_info = product_data["product_info"]
# 生成查询向量
query_embedding = get_titan_embedding(query_text)
query_embedding_array = np.array([query_embedding], dtype=np.float32)
# 搜索最相似的k个向量
distances, indices = index.search(query_embedding_array, k)
# 获取对应的商品信息
similar_products = [product_info[int(idx)] for idx in indices[0]]
return similar_products, distances[0]
四、SEO 优化内容智能创作
有了主题和相关商品信息后,我们可以利用 Amazon Bedrock 的大模型生成高质量 SEO 文章。为了构建完整的 SEO 生态系统,我们还需要提取副关键词并建立内链结构,从而提升整体网站权重。
结构化内容生成
为确保生成内容的安全性和可控性,我们不直接生成 HTML,而是使用预定义的 JSON 格式,再通过前端框架(如React.js/Vue.js)渲染为 HTML(参考:基于亚马逊云科技 Amazon Bedrock Tool Use 实现 Generative UI):
You are an expert SEO content writer. Create a concise, SEO-optimized article based on the following inputs:
Input:
- Main topic: {topic}
- Primary keyword: {primary_keyword}
- Related products: {products_list}
Follow these content guidelines:
1. First, analyze the topic and determine 3-5 relevant long-tail keywords related to the primary keyword
2. Create an engaging title that naturally incorporates the primary keyword
3. Write a 200-300 word article divided into 2-3 paragraphs only (no subheadings)
4. Naturally distribute the primary keyword and long-tail keywords throughout the text
5. Avoid keyword stuffing while maintaining SEO optimization
6. Include natural mentions of the provided products where relevant
7. Provide valuable, practical, and original information
8. Write a compelling meta description (under 160 characters) containing the primary keyword
Return the complete article in the following JSON format:
{
"title": "SEO-optimized title for the topic",
"meta_description": "Under 160 characters meta description including the primary keyword and compelling content",
"keywords": ["primary_keyword", "long_tail_keyword1", "long_tail_keyword2", "long_tail_keyword3"],
"word_count": total_word_count,
"structure": [
{"type": "paragraph1", "content": "First paragraph content"},
{"type": "paragraph2", "content": "Second paragraph content"},
{"type": "paragraph3", "content": "Third paragraph content (if needed)"}
],
"products": [{product1}, {product2}, {product3}],
"internal_linking_suggestions": [{"keyword":"long_tail_keyword1"}, {"keyword":"long_tail_keyword2"}]
}
Make sure all content is original, valuable to readers, and optimized for search engines without sacrificing readability.
前端渲染组件
使用 React.js 组件将 JSON 格式内容转换为结构化 HTML,同时实现内链建设:
import React from 'react';
import PropTypes from 'prop-types';
import './SEOArticle.css';
const SEOArticle = ({ articleData }) => {
const {
title,
meta_description,
keywords,
word_count,
structure,
products,
internal_linking_suggestions
} = articleData;
// 为内容添加内部链接
const addInternalLinks = (text) => {
let linkedContent = text;
// 创建快速查找内部链接建议的映射
const linkMap = {};
internal_linking_suggestions.forEach(suggestion => {
linkMap[suggestion.keyword.toLowerCase()] = suggestion;
});
// 按长度排序关键词(降序),以避免替换较长关键词的部分
const sortedKeywords = Object.keys(linkMap).sort((a, b) => b.length - a.length);
// 用链接版本替换关键词
sortedKeywords.forEach(keyword => {
const regex = new RegExp(`\\b${keyword}\\b`, 'gi');
linkedContent = linkedContent.replace(regex, match =>
`<a href="/articles/${encodeURIComponent(keyword)}" class="internal-link">${match}</a>`
);
});
return linkedContent;
};
// 渲染带有内部链接的段落
const renderParagraph = (content) => {
const linkedContent = addInternalLinks(content);
return <div dangerouslySetInnerHTML={{ __html: linkedContent }} />;
};
return (
<div className="container">
<article className="seo-article">
{/* 文章头部 */}
<header className="article-header">
<h1>{title}</h1>
{meta_description && <meta name="description" content={meta_description} />}
{keywords && keywords.length > 0 && <meta name="keywords" content={keywords.join(', ')} />}
</header>
{/* 文章内容 */}
<div className="article-content">
{structure.map((section, index) => (
<div key={index} className="article-section">
{renderParagraph(section.content)}
</div>
))}
</div>
{/* 产品推荐 */}
{products && products.length > 0 && (
<section className="product-recommendations">
<h2>Recommend</h2>
<div className="products-grid">
{products.map((product, index) => (
<div key={index} className="product-card">
<a href={product.link} className="product-link">
<img src={product.image} alt={product.name} className="product-image" />
<h3 className="product-name">{product.name}</h3>
<p className="product-price">¥{product.price}</p>
{product.rating && (
<div className="product-rating">
{'★'.repeat(Math.floor(product.rating))}
{'☆'.repeat(5 - Math.floor(product.rating))}
<span>({product.reviews})</span>
</div>
)}
<button className="product-cta">shop now</button>
</a>
</div>
))}
</div>
</section>
)}
</article>
</div>
);
};
// 添加PropTypes验证
SEOArticle.propTypes = {
articleData: PropTypes.shape({
title: PropTypes.string.isRequired,
meta_description: PropTypes.string,
keywords: PropTypes.arrayOf(PropTypes.string),
word_count: PropTypes.number,
structure: PropTypes.arrayOf(
PropTypes.shape({
type: PropTypes.string,
content: PropTypes.string.isRequired
})
).isRequired,
products: PropTypes.arrayOf(
PropTypes.shape({
name: PropTypes.string.isRequired,
image: PropTypes.string.isRequired,
link: PropTypes.string.isRequired,
price: PropTypes.oneOfType([PropTypes.string, PropTypes.number]).isRequired,
rating: PropTypes.number,
reviews: PropTypes.number
})
),
internal_linking_suggestions: PropTypes.arrayOf(
PropTypes.shape({
keyword: PropTypes.string.isRequired
})
).isRequired
}).isRequired
};
export default SEOArticle;
最终成果展示
通过上述流程生成的 SEO 优化文章示例:
 |
基于 AWS Serverless 搭建自动化 SEO 内容生成系统
 |
1. 流量挖掘流程
流量挖掘是 SEO 系统的起点,通过以下步骤自动发现高价值关键词:
1.1 自动化触发机制:Amazon EventBridge 按预设时间表发起流量挖掘事件,触发 Lambda 函数执行挖掘任务
1.2 数据源获取:Lambda 从产品数据库批量获取最新商品信息,确保关键词与实际库存同步
1.3 AI关键词提取:通过 Amazon Bedrock 中的大模型智能分析商品信息,提取最具 SEO 潜力的核心关键词
1.4 任务分发:系统将提取的关键词和待处理商品信息分别发送到专用 SQS 队列,实现并行处理
1.5 消息驱动处理:关键词处理 Lambda 函数监听队列,接收并处理关键词消息
1.6 搜索数据获取:系统调用搜索引擎 API(如 Google Keyword Planner),获取真实搜索量和竞争度数据
1.7 数据持久化:将挖掘到的高价值关键词以结构化格式存储到 S3,为后续分析提供数据基础
这种基于事件驱动的架构确保了系统可以根据业务需求自动扩展,同时最大限度减少资源浪费。
2. 商品数据处理流程
为了实现内容与商品的精准匹配,系统需要对商品数据进行向量化处理:
2.1 异步任务监听:专用 Lambda 函数持续监听商品处理 SQS 队列,确保任务及时处理
2.2 大规模处理编排:接收到商品信息后,系统触发 AWS Batch 任务,支持大规模并行处理
2.3 数据获取:Batch 任务从 S3 获取完整商品信息,包括标题、描述、属性等多维数据
2.4 AI 向量嵌入:调用 Amazon Bedrock Titan Embeddings 模型,将商品文本信息转换为高维向量表示
2.5 优化存储:将生成的向量数据和商品元信息以优化格式存储到 S3,支持高效检索
这一流程利用 AWS Batch 的弹性计算能力,可以根据处理需求自动调整资源,实现成本与性能的最佳平衡。
3. SEO 内容创作流程
内容创作是整个系统的核心输出环节,通过 AI 驱动实现高质量、SEO 友好的内容生成:
3.1 定时内容更新:EventBridge 按策略触发内容生成 Lambda,确保网站内容持续更新
3.2-3.3 数据分析与筛选:系统通过 Amazon Athena 对 S3 中的关键词数据进行 SQL 查询,基于搜索量、竞争度等指标筛选最具价值的目标关键词
3.4 搜索意图分析:调用搜索引擎 API 获取 SERP 数据,并使用 Bedrock 大模型进行深度意图分析
3.5 主题向量化:生成的内容主题通过 Titan Embeddings 模型转换为向量表示
3.6 相关商品匹配:系统利用向量相似度搜索,从商品向量库中精准匹配与主题最相关的商品
3.7 AI内容生成:整合主题、商品信息和搜索意图,调用 Bedrock 大模型生成结构化 SEO 文章
3.8 内容分发准备:将生成的文章内容存入 Amazon DynamoDB,支持前端快速访问和内容管理
整个架构采用事件驱动模式,各组件松耦合但紧密协作,确保了系统的高可用性和可扩展性。通过充分利用 AWS Serverless服务,系统实现了零运维、按需扩展和成本优化,为企业提供了一个可持续的 SEO 内容生成解决方案。
总结与展望
本文详细介绍了如何利用 Amazon Bedrock 构建一套完整的 SEO 内容生成系统,从关键词挖掘、搜索意图分析到内容智能创作。这套系统具有以下优势:
- 高效率:自动化流程大幅减少人工工作量
- 低成本:相比传统 SEO 团队,显著降低人力成本
- 数据驱动:基于真实搜索数据,精准把握用户需求
- 内容质量保证:AI 生成内容经过 SEO 优化,同时保持可读性和价值
- 可扩展性:系统架构支持大规模内容生成和管理
随着生成式 AI 技术的不断发展,这套系统还有很大的优化空间。未来可以进一步整合用户行为数据、竞争对手分析等维度,打造更加智能化的 SEO 内容生态系统,为企业带来持续增长的有机流量。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。